Large Language Models (LLMs) have made the ambitious quest for generalist agents significantly far from being a fantasy. A key hurdle for building such general models is the diversity and heterogeneity of tasks and modalities. A promising solution is to unify models, allowing the support of a myriad of tasks and modalities while scaling easily. While few large models (e.g., Flamingo (Alayrac et al., 2022)), trained on massive datasets, can support more than two modalities, current small to mid-scale unified models are still limited to 2 modalities (e.g., image-text, or video-text). The question that we ask is: is it possible to build efficiently a unified model that can support all modalities? To answer this, we propose UnIVAL, a step further towards this ambitious goal. Without relying on fancy datasets sizes or models with billions of parameters, the ~ 0.25B parameter UnIVAL model goes beyond two modalities and unifies text, images, video, and audio into a single model. Our model is efficiently pretrained on many tasks, based on task balancing and multimodal curriculum learning. UnIVAL shows competitive performance to existing state-of-the-art approaches, across image and video-text tasks. The representation learned from image and video-text modalities, allows the model to achieve competitive performance to SoTA when finetuned on audio-text tasks, despite not being pretrained on audio. Thanks to the unified model, we propose a novel study on multimodal model merging via weight interpolation of models trained on different multimodal tasks, showing their benefits for out-of-distribution generalization. We motivate unification by showing the synergy between tasks.
UnIVAL is unified along 4 axes:
Unified model/architecture: we use the same model during pretraining and
finetuning of all tasks, without any task-specific heads. Our model's core is a LM designed to process abstract representations.
We employ an encoder-decoder transformer as LM, due to its effectiveness for multimodal tasks and zero-shot
generalization after multitask training. The LM is enhanced with lightweight modality-specific projections/encoders
that enable the mapping of different modalities to a shared and more abstract
representation space. Each encoder extracts a feature map, which
is then flattened to generate a sequence of tokens. These tokens are linearly projected to match the input
dimension of the LM. In our approach, we opt for CNN encoders as they scale effectively with high-resolution inputs,
minimize the number of output tokens, and exhibit improved efficiency during both inference and training compared to transformers.
Unified input/output format: the input/output of all tasks consists of a sequence of tokens, where we use a unified vocabulary that contains
text, location, and discrete image tokens.
Unified pretraining tasks: to train a single model on many tasks, a unified representation of these tasks is necessary.
We transform all tasks into a sequence-to-sequence format, where each task is specified by
a textual prompt (e.g., "What does the video describe?" for video captioning). For pretraining tasks, we
pretrain on many relatively small public datasets.
Unified training objective: We optimize the model for conditional next token prediction. Specifically, we only use a cross-entropy loss.
We evaluate the model on several multimodal tasks such as: Image/Video/Audio Captioning, Image/Video QA, Visual Grounding, Visual Entailment and Text-to-Image Generation. In the following we present only few results, including some results on multimodal model merging.
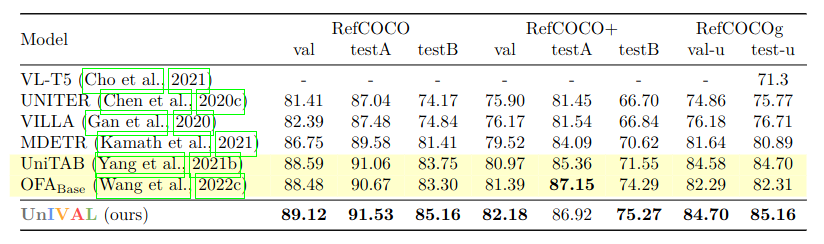
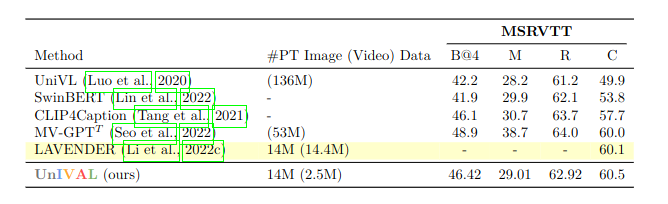
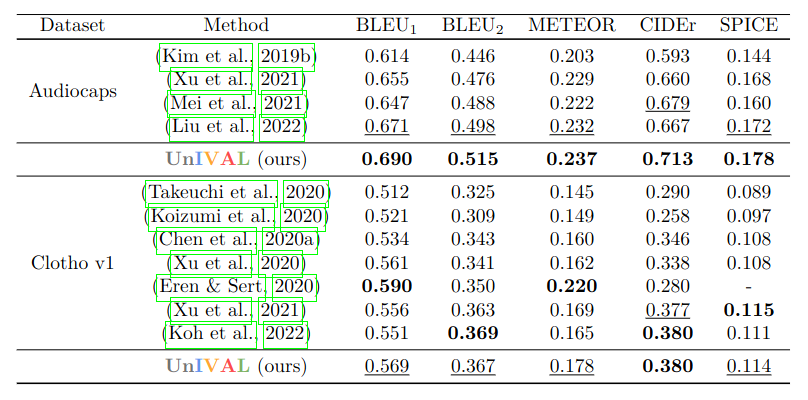
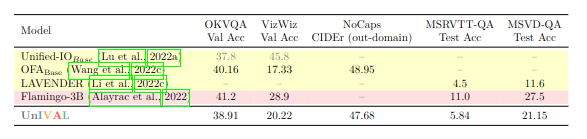
We also evaluate UnIVAL without finetuning on seen and unseen datasets:
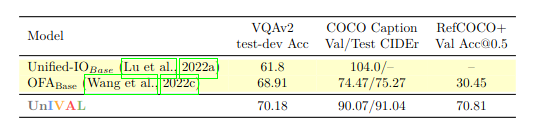
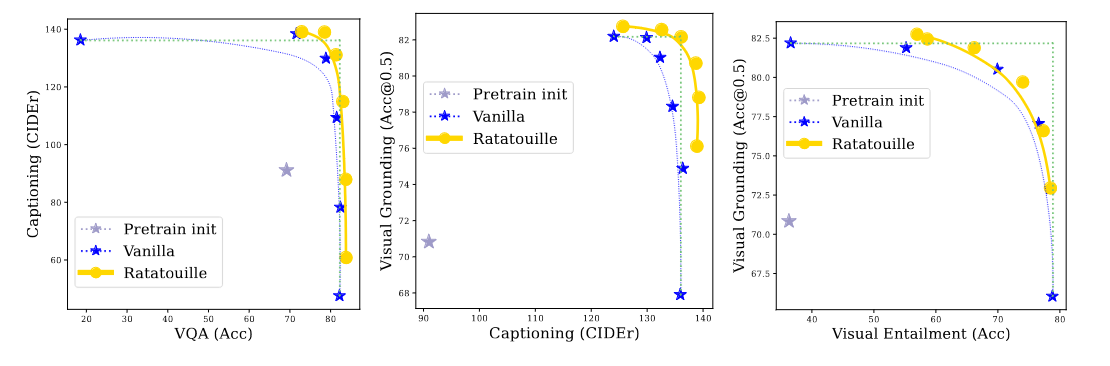
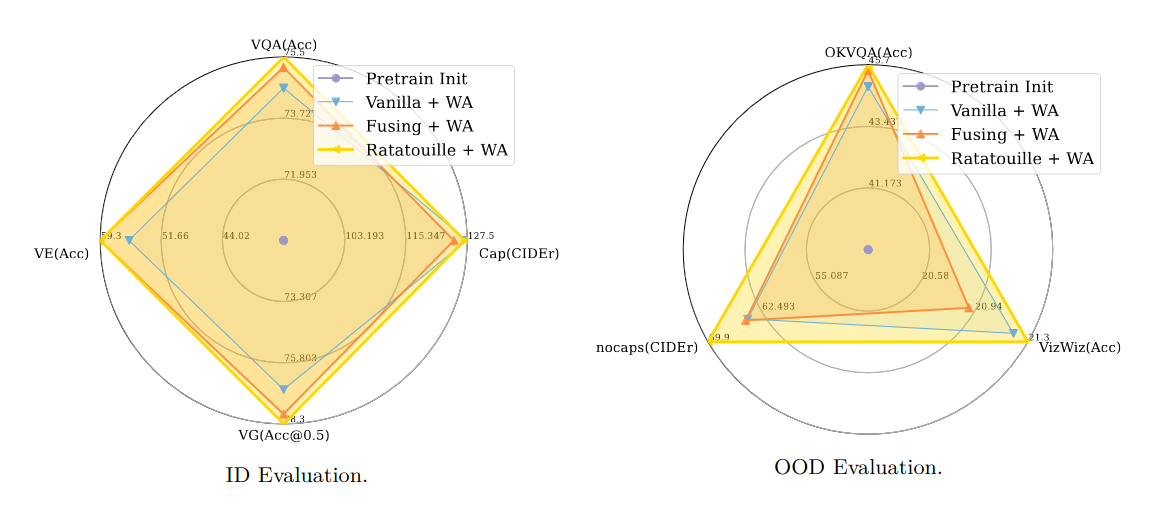
Now we present the results on multimodal model merging. Specifically, we average and interpolate between models trained on different multimodal tasks.
Some qualitative results on image-text tasks.



This work was supprted by HPC resources of CINES and GENCI. The authors would like to thank the staff of CINES for technical support in managing the Adastra GPU cluster, in particular; Jean-Christophe Penalva, Johanne Charpentier, Mathieu Cloirec, Jerome Castaings, Gérard Vernou, Bertrand Cirou and José Ricardo Kouakou. This work was also partly supported by ANR grant VISA DEEP (ANR-20-CHIA-0022).
@article{shukor2023unival,
title={Un{IVAL}: Unified Model for Image, Video, Audio and Language Tasks},
author={Mustafa Shukor and Corentin Dancette and Alexandre Rame and Matthieu Cord},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2023},
url={https://openreview.net/forum?id=4uflhObpcp},
note={}
}
